39 keras reuters dataset labels
Function reference • keras Apply an activation function to an output. layer_dropout () Applies Dropout to the input. layer_reshape () Reshapes an output to a certain shape. layer_permute () Permute the dimensions of an input according to a given pattern. layer_repeat_vector () Repeats the input n times. Datasets in Keras - GeeksforGeeks It consists of 11,228 newswires from Reuters, labelled over 46 topics. Just like the IMDB dataset, each wire is encoded as a sequence of word indexes (same conventions). from keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data () Returns: x_train, x_test: list of sequences, which are lists of indexes (integers).
How to do multi-class multi-label classification for news categories Built a Keras model to do multi-class multi-label classification. Visualize the training result and make a prediction. ... This post we focus on the multi-class multi-label classification. Overview of the task. We are going to use the Reuters-21578 news dataset. With a given news, our task is to give it one or multiple tags. The dataset is ...

Keras reuters dataset labels
How to show topics of reuters dataset in Keras? - Stack Overflow 1 Answer. Associated mapping of topic labels as per original Reuters Dataset with the topic indexes in Keras version is: ['cocoa','grain','veg-oil','earn','acq','wheat','copper','housing','money-supply', 'coffee','sugar','trade','reserves','ship','cotton','carcass','crude','nat-gas', 'cpi','money-fx','interest','gnp','meal-feed','alum','oilseed','gold','tin', 'strategic-metal','livestock','retail','ipi','iron-steel','rubber','heat','jobs', ... Where can I find topics of reuters dataset · Issue #12072 · keras-team ... In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are? Python keras.datasets.reuters.load_data() Examples def load_retures_keras(): from keras.preprocessing.text import tokenizer from keras.datasets import reuters max_words = 1000 print('loading data...') (x, y), (_, _) = reuters.load_data(num_words=max_words, test_split=0.) print(len(x), 'train sequences') num_classes = np.max(y) + 1 print(num_classes, 'classes') print('vectorizing sequence …
Keras reuters dataset labels. Keras for Beginners: Implementing a Recurrent Neural Network Keras is a simple-to-use but powerful deep learning library for Python. In this post, we'll build a simple Recurrent Neural Network (RNN) and train it to solve a real problem with Keras.. This post is intended for complete beginners to Keras but does assume a basic background knowledge of RNNs.My introduction to Recurrent Neural Networks covers everything you need to know (and more) for this ... Keras for R - RStudio The dataset also includes labels for each image, telling us which digit it is. For example, the labels for the above images are 5, 0, 4, and 1. Preparing the Data. The MNIST dataset is included with Keras and can be accessed using the dataset_mnist() function. Here we load the dataset then create variables for our test and training data: keras source: R/datasets.R - R Package Documentation the class labels are: #' #' * 0 - t-shirt/top #' * 1 - trouser #' * 2 - pullover #' * 3 - dress #' * 4 - coat #' * 5 - sandal #' * 6 - shirt #' * 7 - sneaker #' * 8 - bag #' * 9 - ankle boot #' #' @family datasets #' #' @export dataset_fashion_mnist <- function () { dataset <- keras $ datasets $fashion_mnist$load_data() as_dataset_list (dataset) … PDF Introduction to Keras - AIoT Lab from keras.utils import to_categorical trn_labels = to_categorical(train_labels) tst_labels = to_categorical(test_labels) ... Load the Reuters Dataset •Select 10,000 most frequently occurring words 42 from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) =
Datasets - Keras Documentation - faroit keras.datasets.reuters. Dataset of 11,228 newswires from Reuters, labeled over 46 topics. As with the IMDB dataset, each wire is encoded as a sequence of word indexes (same conventions). Usage: (X_train, y_train), (X_test, y_test) = reuters.load_data(path="reuters.pkl", \ nb_words=None, skip_top=0, maxlen=None, test_split=0.1, seed=113) Tutorial On Keras Tokenizer For Text Classification in NLP To do this we will make use of the Reuters data set that can be directly imported from the Keras library or can be downloaded from Kaggle. This data set contains 11,228 newswires from Reuters having 46 topics as labels. We will make use of different modes present in Keras tokenizer and will build deep neural networks for classification. The Reuters Dataset · Martin Thoma The Reuters Dataset Reuters is a benchmark dataset for document classification . To be more precise, it is a multi-class (e.g. there are multiple classes), multi-label (e.g. each document can belong to many classes) dataset. It has 90 classes, 7769 training documents and 3019 testing documents . TensorFlow - tf.keras.datasets.mnist.load_data - Loads the MNIST dataset. This is a dataset of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images. More info can be found at the MNIST homepage. Args path path where to cache the dataset locally (relative to ~/.keras/datasets). Returns Tuple of NumPy arrays: (x_train, y_train), (x_test, y_test).
Multiclass Classification and Information Bottleneck - Medium The Labels for this problem include 46 different classes. The labels are represented as integers in the range 1 to 46. To vectorize the labels, we could either, Cast the labels as integer tensors One-Hot encode the label data We will go ahead with One-Hot Encoding of the label data. This will give us tensors, whose second axis has 46 dimensions. Datasets - keras-contrib Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images. Usage: from keras.datasets import cifar100 (x_train, y_train), (x_test, y_test) = cifar100.load_data (label_mode= 'fine' ) Returns: 2 tuples: x_train, x_test: uint8 array of RGB image data with shape (num_samples, 3, 32, 32). Reuters newswire classification dataset - Keras This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers). Datasets - Keras The tf.keras.datasets module provide a few toy datasets (already-vectorized, in Numpy format) that can be used for debugging a model or creating simple code examples. If you are looking for larger & more useful ready-to-use datasets, take a look at TensorFlow Datasets. Available datasets MNIST digits classification dataset load_data function
127 - Data augmentation using keras - YouTube
Datasets - Keras Documentation - faroit Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images. Usage: from keras.datasets import cifar100 (X_train, y_train), (X_test, y_test) = cifar100.load_data (label_mode= 'fine' ) Return: 2 tuples: X_train, X_test: uint8 array of RGB image data with shape (nb_samples, 3, 32, 32).
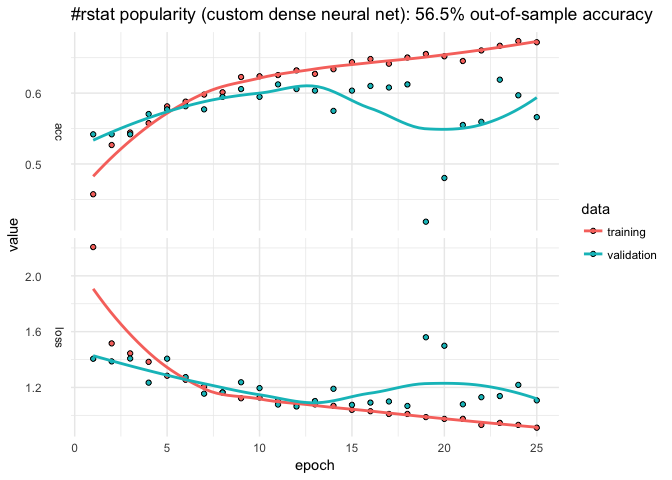
RStudio AI Blog: Analyzing rtweet Data with kerasformula
NLP: Text Classification using Keras - E2E Cloud We have to import these datasets from Keras. After importing, its feature dataset and label dataset are individually stored in two tuples. Each tuple contains both training and testing portions. You can import Reuters dataset from Keras-20 NewsGroups- It is another dataset source, consisting of approx. 20,000 documents across 20 different topics.

Datasets - Keras - YouTube
keras/reuters.py at master · keras-team/keras · GitHub This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this [github discussion] ( ) for more info.
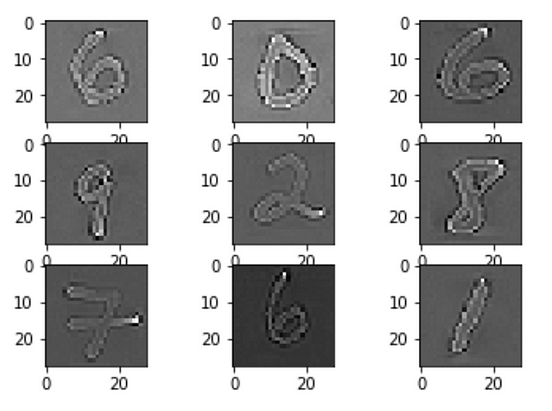
Data Augmentation tasks using Keras for image data | by Ayman Shams | Medium
TensorFlow - tf.keras.datasets.reuters.load_data - Loads the Reuters ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers).

Keras ImageDataGenerator | Keras Data Augmentation | Create image dataset for CNN Deep Learning ...
Is there a dictionary for labels in keras.reuters.datasets? Unfortunately it seems that Keras dataset lacks information about topics. You could use nltk version of the same dataset. You can get topic names there too. Refer to for details. Share edited Jan 27, 2019 at 14:20 answered Jan 27, 2019 at 13:46 Bulat Maksudov 41 3 Add a comment 1

Skip the Data Preprocessing! Accessing 12 Ready-to-Go Datasets | by Andre Ye | Analytics Vidhya ...
Namespace Keras.Datasets - GitHub Pages Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images. FashionMNIST. Dataset of 60,000 28x28 grayscale images of 10 fashion categories, along with a test set of 10,000 images. This dataset can be used as a drop-in replacement for MNIST. The class labels are: IMDB
ImageDataGenerator with no augmentation performs much worse compared to plain arrays · Issue ...
What is keras datasets? | classification and arguments - EDUCBA Reuters classification dataset for newswire is somewhat like IMDB sentiment dataset irrespective of the fact Reuters dataset interacts with the newswire. It can consider dataset up to 11,228 newswires from Reuters with labels up to 46 topics. It also works in parsing and processing format. # Fashion MNIST dataset (alternative to MNIST)

Cara Menampilkan Label Data SHP di ArcGIS (Tutorial Lengkap)
Text Classification in Keras (Part 1) — A Simple Reuters News ... import keras from keras.datasets import reuters Using TensorFlow backend. (x_train, y_train), (x_test, y_test) = reuters.load_data (num_words=None, test_split=0.2) word_index = reuters.get_word_index (path="reuters_word_index.json") print ('# of Training Samples: {}'.format (len (x_train))) print ('# of Test Samples: {}'.format (len (x_test)))

Building your First Neural Network on a Structured Dataset (using Keras ... Load Data: Here, I'll import the necessary libraries to load the dataset, combine train and test to perform preprocessing together, and also create a flag for the same. #Importing Libraries for ...

KerasでのData Augmentationの解説 – S-Analysis
Classifying Reuters Newswire Topics with Recurrent Neural Network The purpose of this blog is to discuss the use of recurrent neural networks for text classification on Reuters newswire topics. The dataset is available in the Keras database. It consists of 11,228...

Python keras.datasets.reuters.load_data() Examples def load_retures_keras(): from keras.preprocessing.text import tokenizer from keras.datasets import reuters max_words = 1000 print('loading data...') (x, y), (_, _) = reuters.load_data(num_words=max_words, test_split=0.) print(len(x), 'train sequences') num_classes = np.max(y) + 1 print(num_classes, 'classes') print('vectorizing sequence …

Keras - Algorithmia Developer Center
Where can I find topics of reuters dataset · Issue #12072 · keras-team ... In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are?

How to show topics of reuters dataset in Keras? - Stack Overflow 1 Answer. Associated mapping of topic labels as per original Reuters Dataset with the topic indexes in Keras version is: ['cocoa','grain','veg-oil','earn','acq','wheat','copper','housing','money-supply', 'coffee','sugar','trade','reserves','ship','cotton','carcass','crude','nat-gas', 'cpi','money-fx','interest','gnp','meal-feed','alum','oilseed','gold','tin', 'strategic-metal','livestock','retail','ipi','iron-steel','rubber','heat','jobs', ...

Rhyme - Project: Multilayer Perceptron Models with Keras
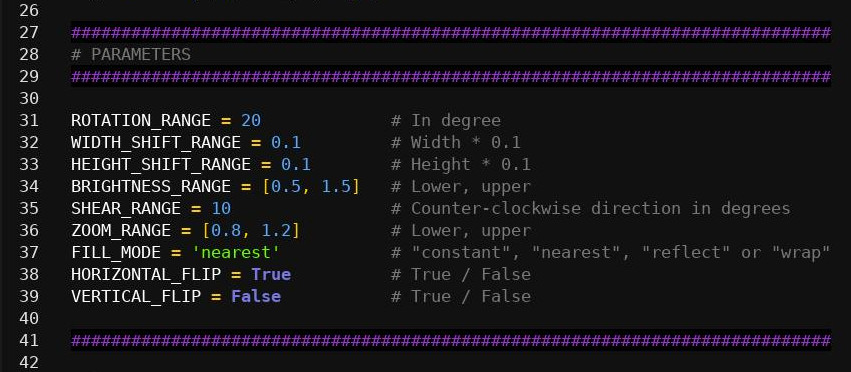
GitHub - bedna-KU/Controlled-data-augmentation-with-Keras: + blur and noise
Post a Comment for "39 keras reuters dataset labels"